
In this post, I’m going to talk about what Sagefy is. Where Sagefy was in October last year. And why and how I changed Sagefy in the time since. I wanted to share how this big change went down. And document the changes for my future self.
What is Sagefy
Sagefy is an open-content adaptive learning platform. Anyone can learn anything, and Sagefy adapts the content to the learner’s knowledge and goals. Sagefy is open-content, meaning anyone can view, create, edit, and share learning content. Sagefy is adaptive, meaning as you learn, Sagefy changes which learning activities it picks to fit your needs. Sagefy is open-source and freely available.
Where Sagefy was in October 2018
I’ve been working on Sagefy since April 2013.
| A 2017 image of the homepage. | A 2018 image of the choose unit page. |
|---|---|
 |
 |
Sagefy in October 2018 had lots of features. It was quite capable. Despite being operational for a few years, there was litle human traffic to the site each day. There was about one account sign up per day. And in this version, as users needed accounts for most parts of the site, sign ups were a decent indicator of use. Which is to say, not much use at all.
I’m a fan of usability testing and user interviews. Sagefy has had many of each. The feedback I got was:
- I don’t want to make an account to try it out.
- It doesn’t have the learning content that I want.
- I don’t understand what units and subjects are. (At the time there were 3 types of things: cards, units, and subjects.)
- I don’t understand how to make content. (And this was after several iterations of the content creation parts of the site.)
Additionally, referral traffic was very low. Some of the technical choices made it difficult to optimize for search engines.
On the technical side, I had an isomorphic rendering – JavaScript on client and server – with a small virtual-dom library. I had a Python server running REST endpoints with lots of raw SQL and home-built code. And endpoint logic to manage and update in several places with each change. Lots of endpoint logic. And I had three databases, PostgresQL, Redis, and Elasticsearch. All sitting behind an Nginx instance. Test builds were slow, but thorough. In later iterations I was using Docker and Docker Compose. This was all gravy, don’t get me wrong. It worked, and performed reasonably well. But change wasn’t always easy.
Why I wanted to change Sagefy
I decided in October 2018 it was time for a bigger change. I’m the first to argue for aggressive refactoring instead of rewriting a whole application. But as Sagefy is a side project, and with low traffic. The risks were lower with a rewrite. I also spent quite a bit of time the prior months trying to iterate the architecture to support anonymous – not logged in – users learning and making content. It was a ton of work, with no obvious end in sight.
So with “fuck it, I’m going to rewrite Sagefy” being where I was, here were my goals:
- Make Sagefy work with or without an account.
- Make it easier to make new content.
- Find a way to get lots of content quickly.
- Focus on leading people to the site with content that will get links and search engine traffic.
- Reducing the number of concepts and features.
- Figure out how to write way less code to make changes faster, so I can adapt to user feedback faster.
How the Sagefy changed
Mocks
My first action was to create some mocks for Sagefy. I wanted to figure out where I was going. I wanted to iterate fast.
I did these in plain HTML, with the world’s most basic CSS sheet. I know HTML better than any design tool at this point. I used no CSS classes, only the standard tags with light inline styling. I published them on GitHub Pages for hosting. And I wanted to get feedback early, before any real technical investment.
I started with the home page and subject pages, as those are the two pages that will start the user experience. I focused on flows rather than features. Ensuring the user always has a clear next action to take. I also wanted to make sure when people end up in “null states”, there’s something for them to do. For example, today when you search for a subject in Sagefy and you can’t find anything: it prompts you to go ahead and make a new subject. While keeping the above goals and mind. And editing. Lots of editing out features and capabilities. I focused on the main goal: to let anyone learn anything they want, adapted and free.
I requested review and feedback from my email list, and I had 3 users take the time to investigate, review, and provide feedback. (Thank you!) Every point was valid and helped focus the mocks even further. I had some former colleagues and friends review the mocks as well. With the mocks being basic HTML and CSS, I could iterate with each round of feedback fast.
Database and GraphQL service
The thought of having to rebuild everything the way it was in V1 was overwhelming. So much code! The thought occurred to me: I only want to define a schema that describe the whole application. And then from the schema come to life. That’s about the least amount of code you can write and make something reasonably useful.
I looked at some tools on GitHub that were trying to be exactly that… but the finished products were not amazing. Many of these tools were using advanced PostgresQL features to define their schemas. Then I started seeing tools that made entire APIs from the PostgresQL schema: Hasura, PostgREST, and where I am now, which is Postgraphile. When I read the schema design doc on Postgraphile’s website, I felt immediately this would work. The business logic is entirely encoded in Postgres – including authentication and access control. PostgresQL is in practice the only major database that could pull something like this off. Postgraphile makes a GraphQL endpoint automatically from this. I found this appealing. I like both REST and GraphQL. But GraphQL would mean iterating later would often mean no schema change and no new service code for new features. It was ideal.
Another advantage would be cutting down from three databases to one. Postgres and JWTs would handle everything Redis did to manage authentication and caching. Postgres can also do full text searching at nearly the speed of Elasticsearch.
I foolishly decided to try to write the entire database schema up front. This was going on while the mocks were iterating too. My first pass was a draft. I tried to think through the business logic. And I tried to figure out how it would work in PostgresQL and Postgraphile. My second pass was simply trying to make it valid SQL code that the database wouldn’t error trying to load up. I got through that.
Then I tried loading up Postgraphile for the first time against the database. It actually worked. But the schema it generated didn’t make sense to me in a lot of ways. I made some assumptions about how Postgraphile worked, that didn’t turn out to be true. Postgraphile actually does quite a bit more than I thought it would. It predicted lots of little things too, like wanting names to in underscores in PGSQL but camelcase in GraphQL.
February 2019
I realized finishing the whole site and then launching it was never going to happen. It would be too much work. I should have known better, but I was eager. With so little usage, I decided to hard pull the plug on V1 and start over. I redeployed the site with only a home page. Some static text about what Sagefy is, a few links, and an email newsletter sign up.
Serving HTML
I focused on front-end code for a long time. I hate fighting the browser. I love the browser. I wanted to go along with how the browser wants to do things instead of trying to force to go a certain way. This would mean less code and faster iteration.
For the first V2 deployment, I only had the client side running. I decided on JavaScript again for the HTML server. Postgraphile itself is in JavaScript, and its the language I know best. Sure, its a weird, messy language. But its the most popular programming language. So lots of people know it. And the packages available are amazing. And performance-wise, its nearly in the range of Go or Java. Without having to deal with lower level issues, like pointers or verbose static typing.
For my templating language… I chose React. I figured to get started, I would do a simple, server-sends-all-the-HTML sort of site. There’s no front end, browser facing JavaScript at all. I know React super well, and there’s tons of other people that do too. Its tooling is excellent, and so is the ESLint plugin for it. There’s low risk of injection or having an extra close tag. And performance wise, React on the server is about as fast as any other JavaScript HTML templating library. I figured eventually if I wanted to do isomorphic again, it would be easy to convert. That hasn’t happened though. I’ve been able to build everything with plain old HTML and no JavaScript running in the browser.
I did the mocks with the idea that I would make a more designed looking site based on them. But instead, I kept the bare-minimum CSS sheet I had. I converted it to its own repository so I could reuse it throughout Sagefy’s docs and my personal site too. I also took out my inline styles and made them into a handful of tiny utilities, like centering text or inlining lists. This approach makes change super easy. I use basic HTML tags. I don’t have to remember a bunch of classes to make the site look decent. Lots of the popular style libraries avoid changes on basic HTML tags to try to be neutral. By having an opinion, I can dramatically reduce how much CSS there is to manage. The site looks consistent without me trying much at all. I can change things so easily, because the site is so basic. And the performance is of course amazing. No custom fonts to load either.
Feature-by-feature
After that initial page was up, I rebuilt the site feature by feature. The whole technical stack was working.
The first feature I did was restoring accounts, so that people could sign up, log in, and log out again. This was the first feature because everything else later would depend on the authentication model.
Each feature had a pattern.
- First, I write the database migration. I’m using a simple Go tool to manage database migrations. The tool operates on straight up raw SQL, no other languages required to use it. The database migrations were easiest to do first in the PostgresQL command line REPL. Then once I get them working I formalize them into a migration.
- After that, I’d use the GraphiQL instance that comes with Postgraphile to write the GraphQL query. This was to ensure the database did what I thought it would.
- Once the query was working, it was on to the client. I start with the Express endpoint, making the appropriate calls to to GraphQL server and handling the result.
- Then I’d write the page in basic HTML with React.
As of this writing, I’ve avoiding DRYing the client code up too quickly. So there’s still lots of copy-paste code. I’ve learned over the years to wait a little on getting DRY. If you abstract too early, then the abstraction needed won’t be as obvious.
This pattern worked for every feature afterwards. And its very little code for the amount of capability it has. Most of the working code is either in PostgresQL … which SQL can do an amazing amount with little code … or in Express endpoints, which I want to work to reduce that even more and rely on PostgresQL instead.
Then the feature order was…
- After the basic account flows existed, I prioritized getting subjects on the site. I used some samples I paid people to make on mechanical turk a few years ago.
- Searching for subjects.
- Being able to add those subjects to your account.
- Create a new subject… whether you have an account or not.
- Uploading the cards I had from the previous version.
- Creating the learning experience again. I used a simplified Bayesian model with statically set parameters to get something out the door.
- Creating cards for subjects, and prompting users to make cards when a subject doesn’t have any or enough.
- Optimizing pages for search engine indexing and linking.
- Created talk pages for cards and subjects.
(If you want to read more about it…)
Content
At this point, I addressed many of the goals already:
- Sagefy works with or without an account.
- Its easy to make new content, and Sagefy prompts users to make content when appropriate.
- Reduced the number of concepts and features: units were gone, as well as many of the database tables that supported V1 features. Units are now subjects with no child subjects, so now there’s only two types of things in the system.
- Way higher search engine optimization and social media linking capabilities.
- Way less code to make changes faster, making new features very fast to finish and iterate.
The big one I didn’t have yet was:
- Users can’t find the content they want.
So I got a little “creative”. I used the Library of Congress system to create a list of subjects and their parent/child relationships. I used the Library of Congress due to its thoroughness. The Library of Congress system is much more systematic than Dewey decimel or other systems. Wikipedia isn’t quite a structured so there’s both not as many but too many subjects at the same time. Then with that list, I used Amazon Mechanical Turk. Again, maybe not my favorite system but with almost no budget, you make compromises. I had the workers pull some basic information about each topic: a definition, a few subtopics, a few scholars in the area, and why you’d want to learn about the topic. The results are pretty good. And I got those uploaded to the site, which means Sagefy as 1500+ new subjects.
But the subjects were all empty. I didn’t want to rely on Mechanical Turk again. It would have been too expensive to go down that road for cards anyway. So I learned some natural language processing. I made a small Python script to search Wikipedia to find the matching page for the subject, summarize it, make multiple choice questions. And then also called other APIs to get a YouTube and a Vimeo video. The quality is pretty variable, but its better than nothing for sure.
Remaining features
Now that there was some content to get indexed and draw more people to the site, I went back to wrap up the remaining features in the mocks:
- Editing subjects and cards
- History pages for subjects and cards
- Site wide search
- Viewing contributions on the dashboard
Where Sagefy is in July 2019
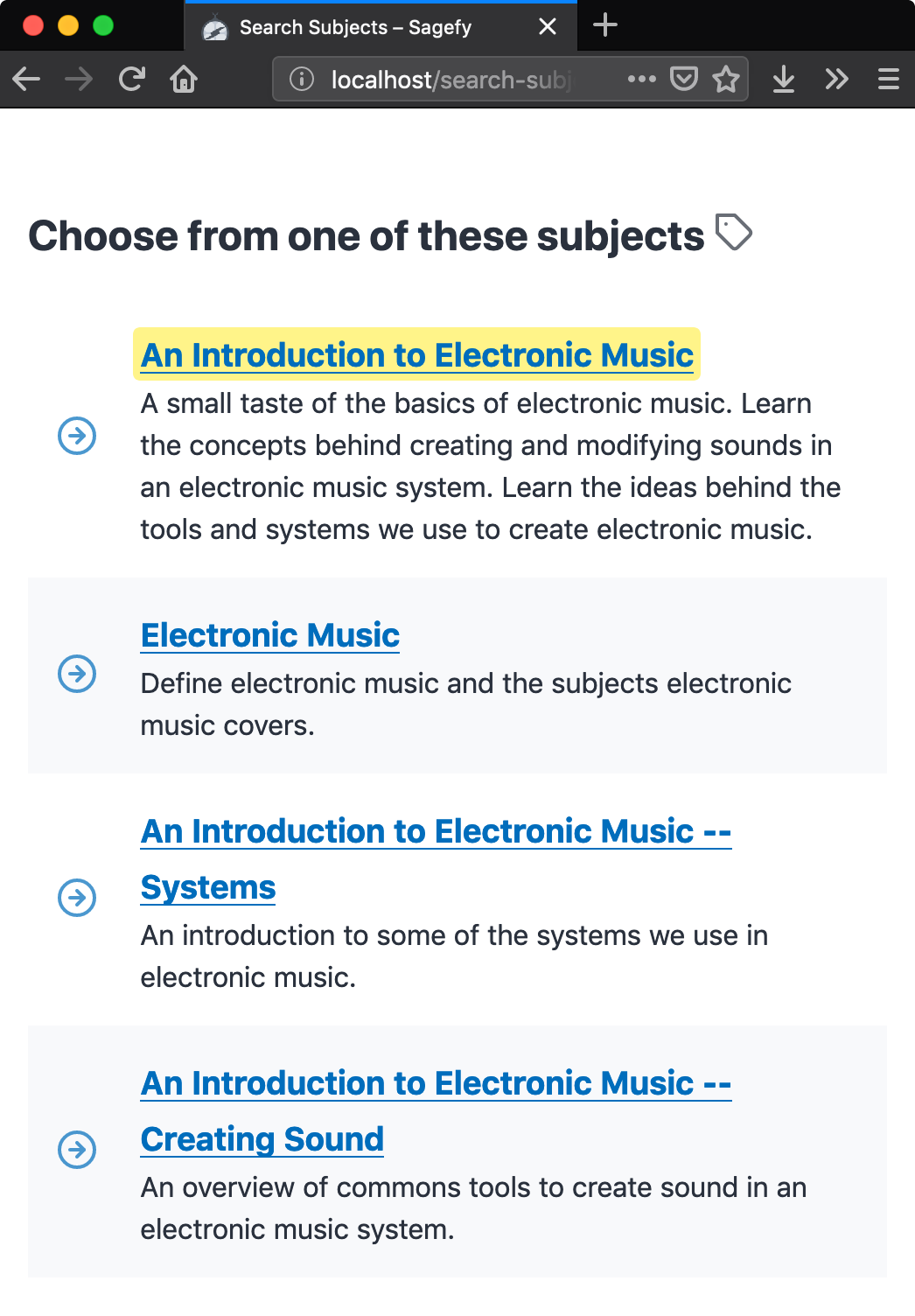
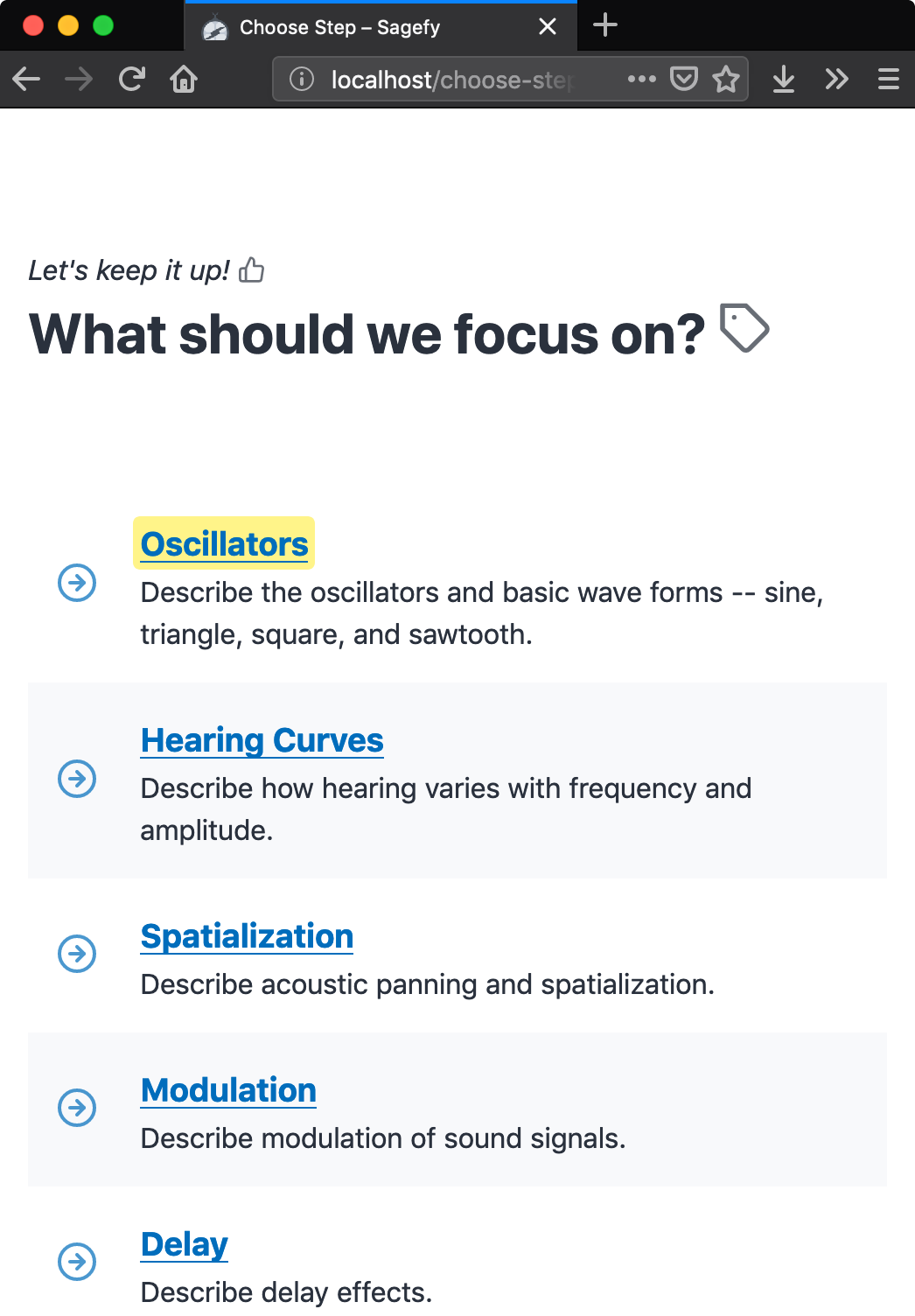
| 1. Search for a subject | 2. Find your subject | 3. Choose the next step | 4. Learn! |
|---|---|---|---|
 |
 |
 |
 |
Sagefy has every feature that was in the mocks. It’s got lots of content, covering almost every significant academic subject. And some cards in each subject as well. The quality of the content is highly variable. Sagefy is available to all users – with or without an account. And available to search engines and linkable. Every day the traffic is growing.
I’m satisfied with the change. I’m happy I did a rewrite, even though its usually a bad strategy. I’m happy I focused on user feedback instead of dreaming. I’m glad I started with very basic mocks. And even though its sort of compromising, focusing on search engines and social media linking does produce results. It took some time to figure out how to do this with the least amount of code, but it was time well spent.
If I were to do it again, I would do even more usability testing and feedback rounds. I would not try writing the whole database schema up front. Instead I would start from day one going feature-by-feature, flow-by-flow. Its so easy to change if you make a mistake, especially at small traffic. And finally, I would have created content earlier, to get more traffic earlier on while I was building features. Instead of the reverse. Content is what gets people to your site, after all.
Where Sagefy will go from here
I have no idea :) Now seems like a good time to pull back a little on the project. Observe how it does in the wild for a few weeks. After that, I’m going to go back to usability testing and interviews. And look over traffic data. This will help me to find out where the next biggest opportunities are. Sagefy is far from perfect for sure. The content could be much better, and the code could use some refactoring and automated tests. But I know when those new opportunities come, its going to be much easier and faster to change. And hopefully I won’t need another rewrite for a long time :)
- Visit Sagefy. Feedback is welcome!
- Watch this 3 minute YouTube video.
- Sign up for updates.
- Follow Sagefy on Twitter.